The Sound of Genre: Visualizing Spotify's Audio DNA
Using R and ggplot2 to compare 114,000 Spotify tracks across 125 genres — finding the audio fingerprints that make each genre sound distinct.
Overview
For my second portfolio project I wanted to work in a different language
and lean into a different strength: visualization. R's ggplot2 is
widely considered the gold standard for statistical graphics, and Spotify's
audio feature data is rich enough to tell several stories at once. Using a public
Kaggle dataset of 114,000 tracks tagged with audio metrics (danceability, energy,
valence, acousticness, and more), I produced three charts that together describe
how genre, mood, and popularity show up in the underlying data.
Tools: R (tidyverse, ggplot2), RStudio.
Finding 1: Every genre has a distinct audio fingerprint
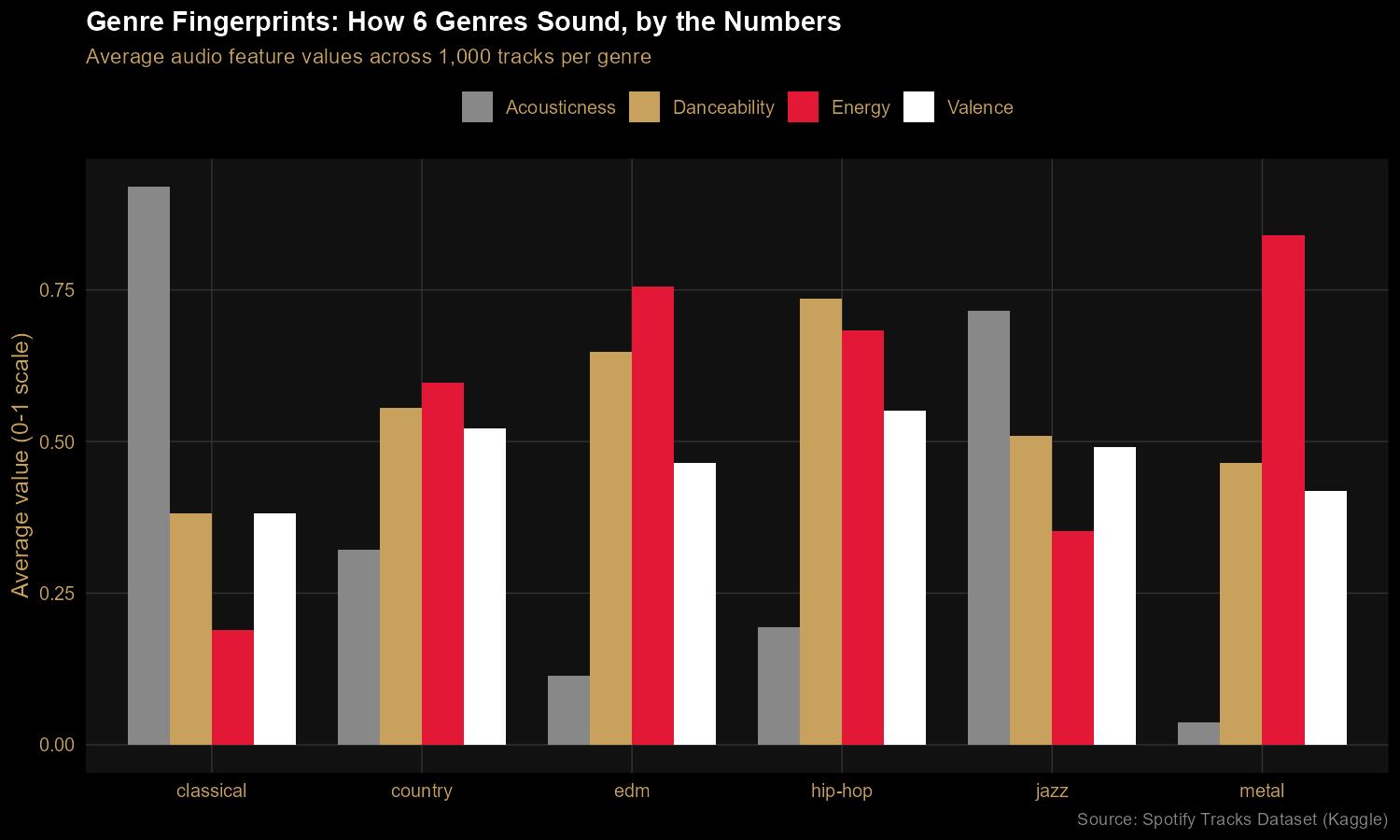
Six genres, four audio features, one chart. Classical lives in a near-pure-acoustic, low-energy bubble. Metal is the energy outlier. Hip-hop leads on danceability. Country and jazz sit closer to the middle, blending features in different proportions. The chart makes audible characteristics visible — anyone reading it can match the bars to their mental model of each genre.
Finding 2: The Mood Map separates genres by energy and emotion
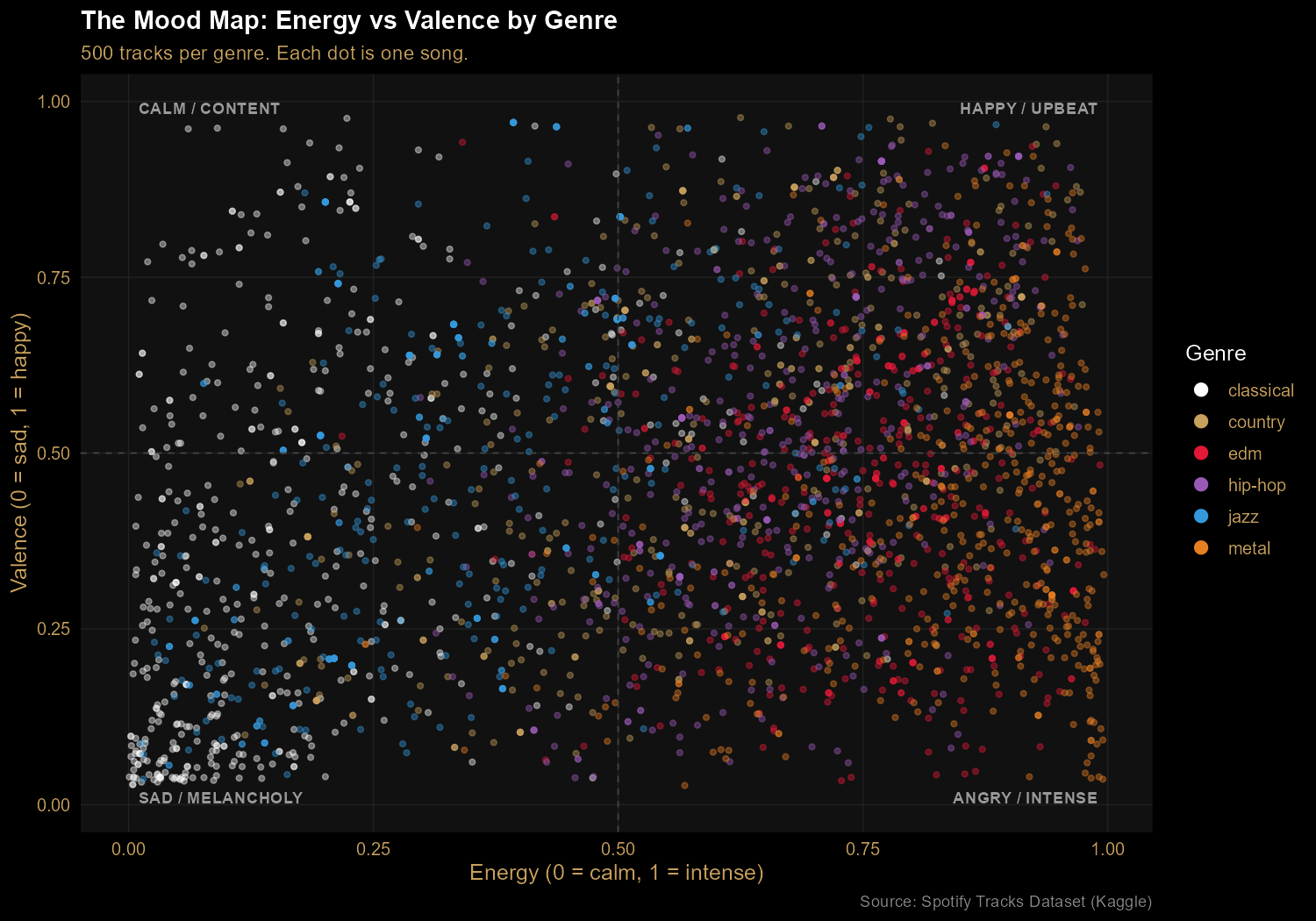
Plotting energy against valence (musical positivity) reveals four mood quadrants. Classical clusters in the calm/melancholy bottom-left. Metal lives on the right side (high energy), spanning both happy and angry valences. EDM tilts toward upbeat. Hip-hop spreads across the entire valence range — the most emotionally diverse genre in the sample. Every dot is a real track; every cluster is a genre's emotional signature.
Finding 3: Hits favor energy and movement, not happiness
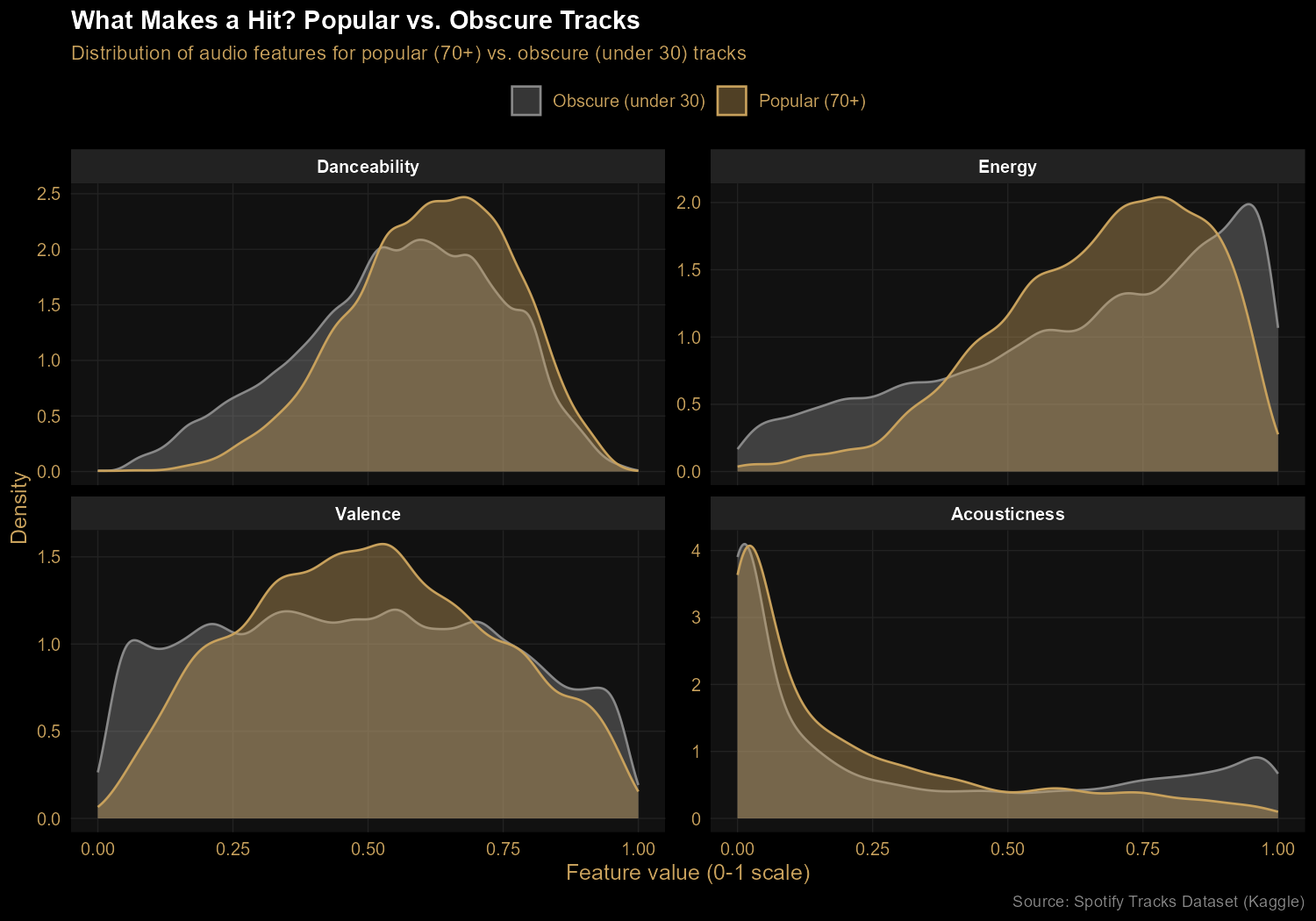
Comparing popular tracks (popularity 70+) against obscure ones (under 30) reveals real but modest patterns. Hits skew toward higher energy and slightly higher danceability. Acoustic tracks are rare among hits — pure acoustic music doesn't dominate Spotify charts. The biggest surprise: valence (positivity) shows almost no difference between popular and obscure tracks. People listen to all moods at all popularity levels. The idea that "happy songs sell" turns out to be wrong, at least in this data.
The Code
The first half of the work is data preparation. With the tidyverse pipe
operator (|>), the transformations read like English — take the data,
filter to selected genres, group, summarize, then reshape:
chart1_data <- df |>
filter(track_genre %in% selected_genres) |>
group_by(track_genre) |>
summarise(
Danceability = mean(danceability),
Energy = mean(energy),
Valence = mean(valence),
Acousticness = mean(acousticness)
) |>
pivot_longer(
cols = -track_genre,
names_to = "feature",
values_to = "value"
)Then ggplot2 builds the chart layer by layer. Each + adds one piece — the geometry, the color scale, the labels, the theme. It's a more declarative approach than matplotlib's procedural style:
ggplot(chart1_data, aes(x = track_genre, y = value, fill = feature)) +
geom_col(position = "dodge", width = 0.8) +
scale_fill_manual(values = c(
"Danceability" = "#C8A15C",
"Energy" = "#E31837",
"Valence" = "#FFFFFF",
"Acousticness" = "#888888"
)) +
labs(
title = "Genre Fingerprints: How 6 Genres Sound, by the Numbers",
subtitle = "Average audio feature values across 1,000 tracks per genre",
y = "Average value (0-1 scale)"
) +
theme_minimal(base_size = 12)Takeaways
This project leaned into R's two biggest strengths: expressive data manipulation with the tidyverse and polished visualizations with ggplot2. Compared to the equivalent matplotlib work in my cinema project, ggplot2 produces noticeably more refined charts with less code — and faceting (splitting one chart into multiple panels) is a single line in R rather than a manual loop. Each tool has its strengths; doing this second project in R let me feel them firsthand.
Code available on GitHub.